
PostgreSQL Database Indexing Introduction
First of all, I write about Relational Database Management System (RDBMS) PostgreSQL and why use database index and what is database index and how to use database index. Because this is one of the most important things to understand when developing Backend Service (REST API Service). If you haven't install PostgreSQL on your device then you can read this tutorial and if you prefer using GUI then you can use DBeaver or tool you love.
What is PostgreSQL
PostgreSQL (often called Postgres) is a powerful, open-source relational database management system (RDBMS). It is designed to handle complex queries and large amounts of data while supporting advanced features like indexing, data types, and extensibility.
What is Database Indexing
Database indexing is a technique used to improve the speed of data retrieval operations in a database. An index is a data structure that provides quick access to rows in a table, similar to an index in a book that helps you quickly find the page containing the information you need.
Why do you need Database Indexing
Database indexing is a critical optimization technique used to enhance the performance of data retrieval operations. Without indexing, retrieving specific data from a database can become slow and resource-intensive, especially as the size of the database grows.
Let's Get Started
Let's make a simple use case, there's a company need to save or manage the employee data. So let's create the table and insert the data.
-- Create a table for storing employee data
CREATE TABLE employee (
id SERIAL PRIMARY KEY,
full_name VARCHAR(255) NOT NULL,
nick_name VARCHAR(255) NOT NULL,
email_address VARCHAR(255) NOT NULL,
created_at TIMESTAMPTZ DEFAULT CURRENT_TIMESTAMP,
created_by VARCHAR(255) NOT NULL,
last_updated_at TIMESTAMPTZ DEFAULT CURRENT_TIMESTAMP,
last_updated_by VARCHAR(255) NOT NULL
);
-- populate data in employee table (1 million rows)
WITH random_data AS (
SELECT
i,
(ARRAY['Alice', 'Bob', 'Charlie', 'David', 'Emma', 'Frank', 'Grace', 'Hannah'])[ceil(random() * 8)::int] AS first_name,
(ARRAY['Johnson', 'Smith', 'Williams', 'Brown', 'Taylor', 'Anderson', 'Thomas'])[ceil(random() * 7)::int] AS last_name,
(ARRAY['AJ', 'Bobby', 'Charlie', 'Davy', 'Em', 'Franky', 'Gray', 'Han'])[ceil(random() * 8)::int] AS nick_name
FROM GENERATE_SERIES(1, 1000000) AS i
)
INSERT INTO employee (full_name, nick_name, email_address, created_by, last_updated_by)
SELECT
first_name || ' ' || last_name AS full_name,
nick_name,
LOWER(first_name || '.' || last_name) || SUBSTRING(md5(random()::text || i::text), 1, 5) || '@example.com' AS email_address,
'admin',
'admin'
FROM random_data;
-- Select the employee table to verify it
-- and it is okay to customize the limit number
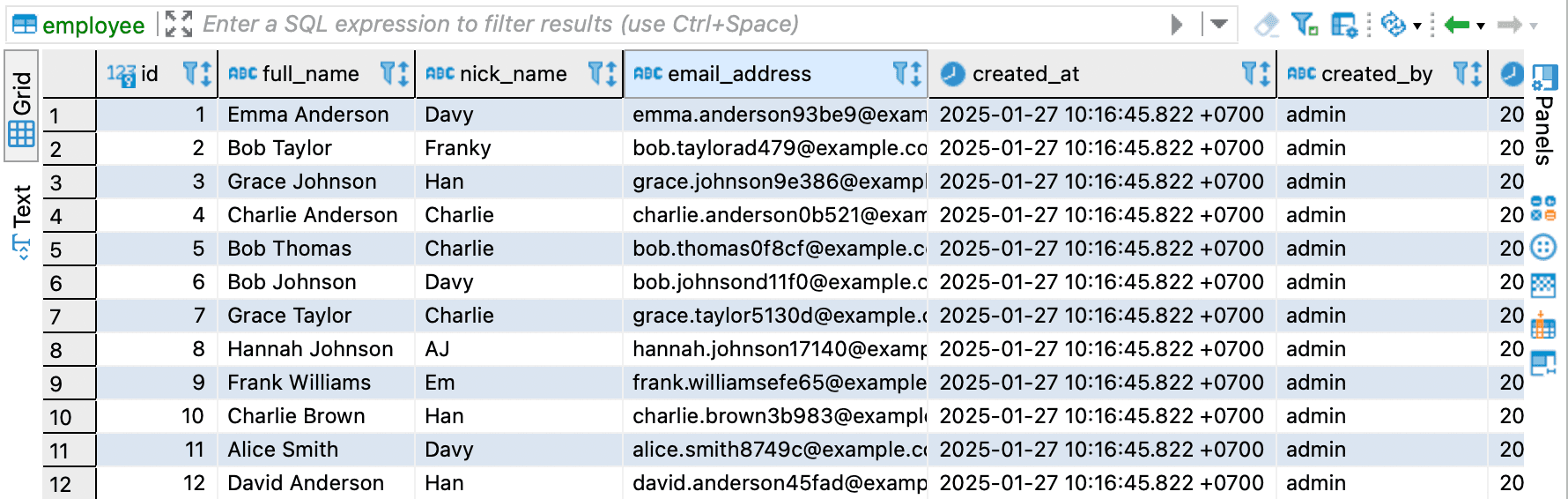
SELECT * FROM employee LIMIT 10;
The query result should look like this
Learn about Database Index
Let's assume there is a need to get the employee data from database by using column email_address. Let's try out some select query.
- First query and result
SELECT * FROM employee e WHERE e.id = 102234;

- Second query and result
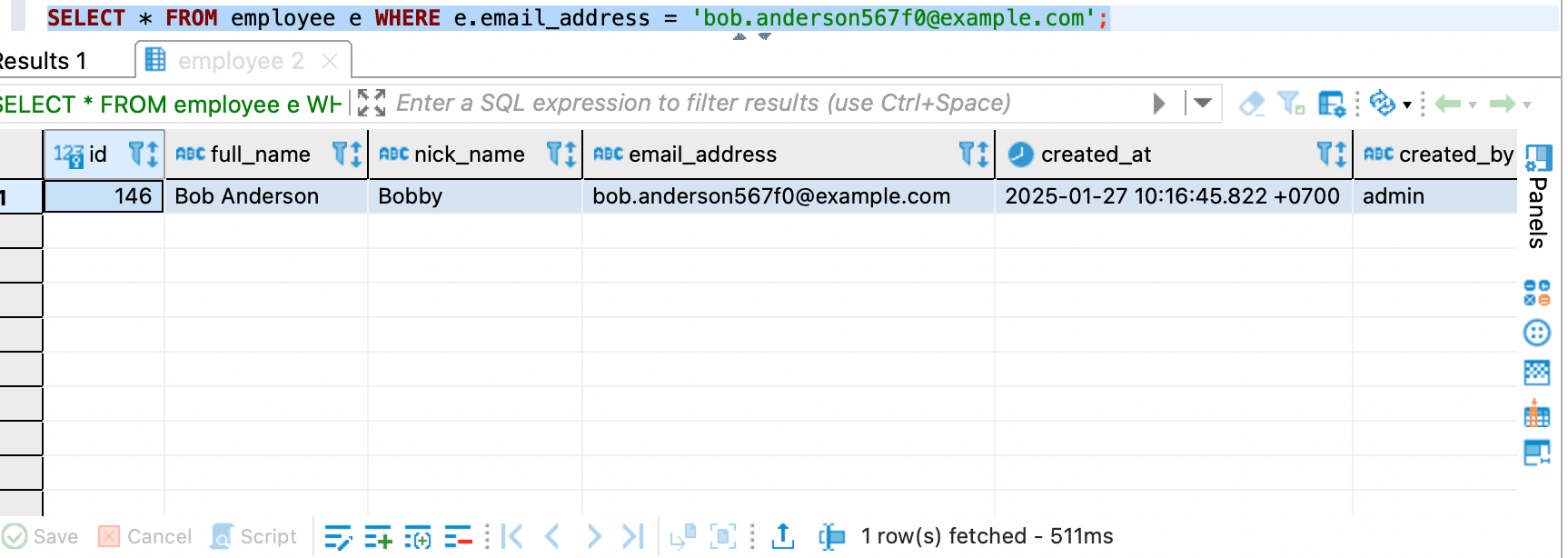
SELECT * FROM employee e WHERE e.email_address = 'bob.anderson567f0@example.com';
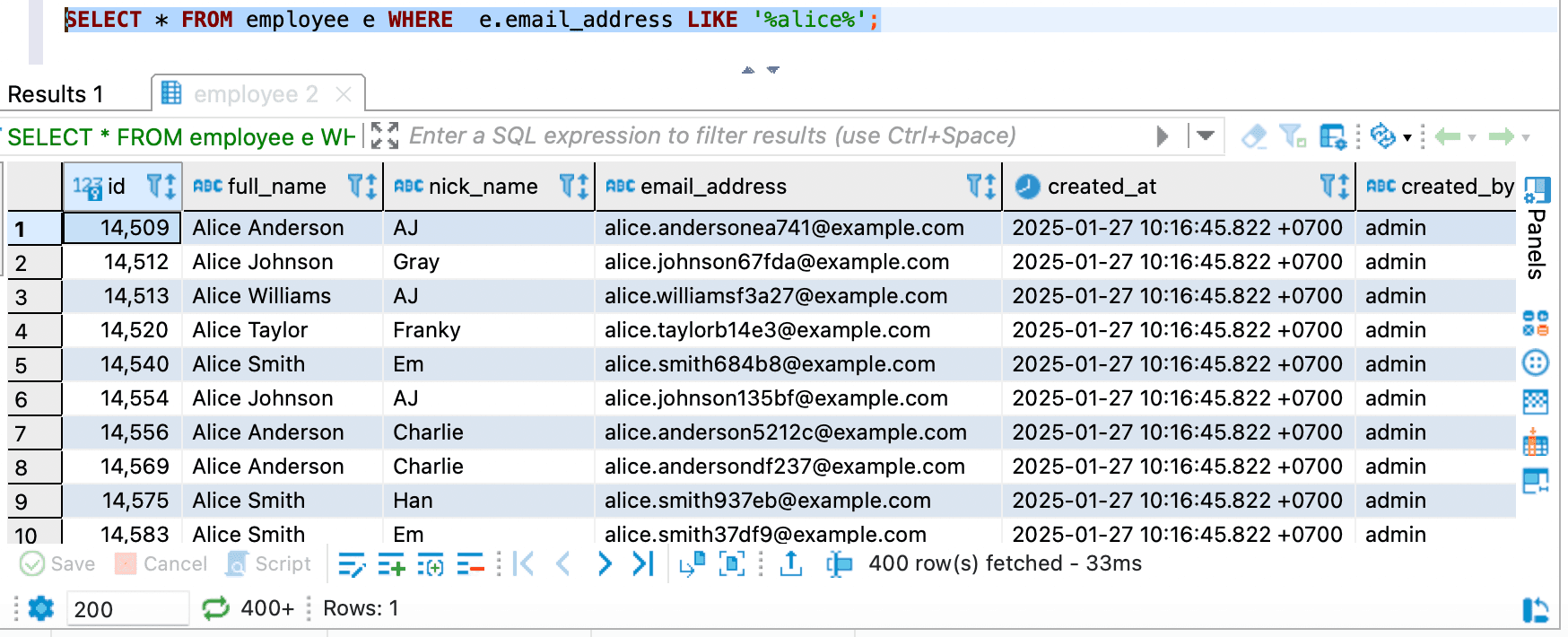
- Third query and result
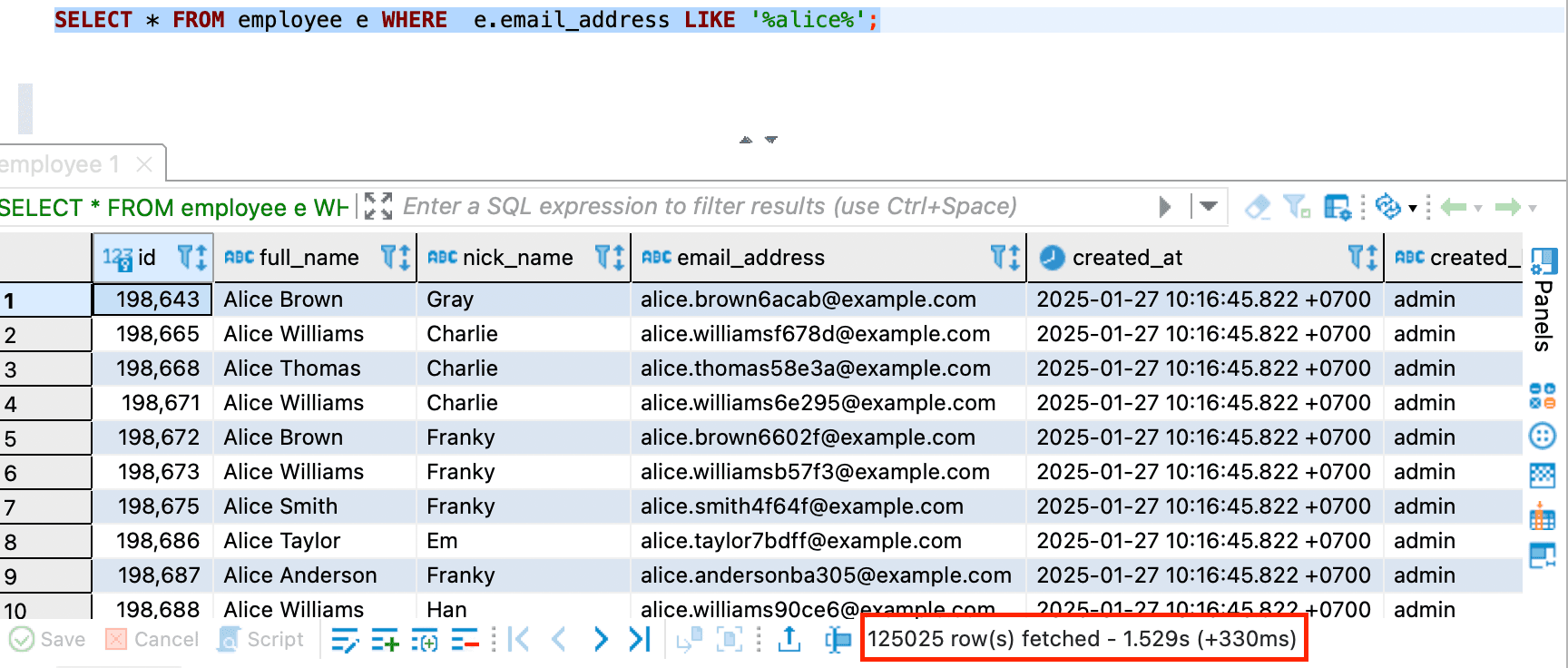
SELECT * FROM employee e WHERE e.email_address LIKE '%alice%';
Let's recap
Every query looks good and fast. So what’s the point of database indexing?
As you can see in the image Third query, it is written 400 row(s) fetched which means
DBeaver does not fetch all the rows that match with the condition WHERE e.email_address LIKE '%alice%' in the table.
So it means DBeaver is limiting fetch size for us.
If you are using DBeaver then please follow this to fetch all rows.
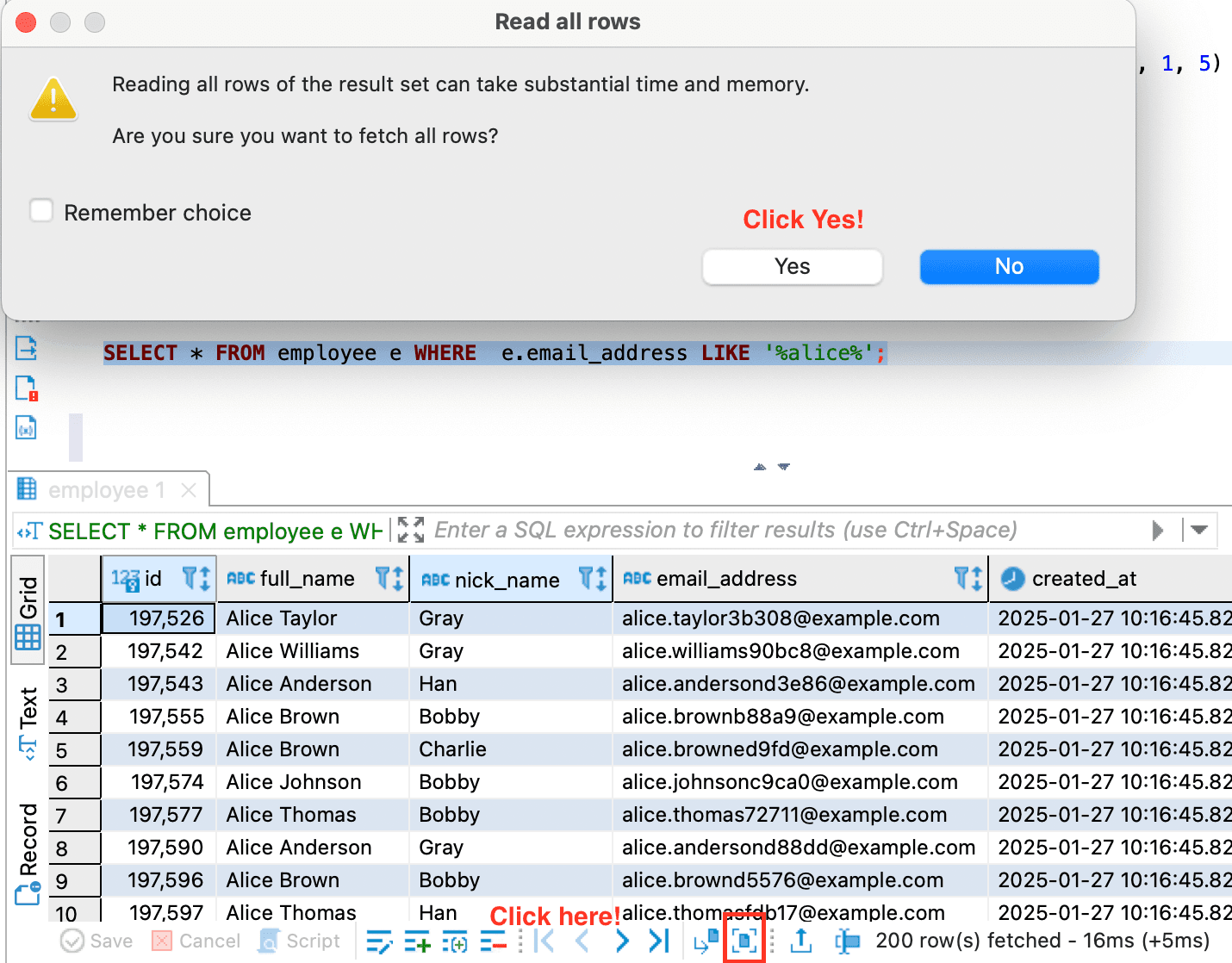
and the results are like this
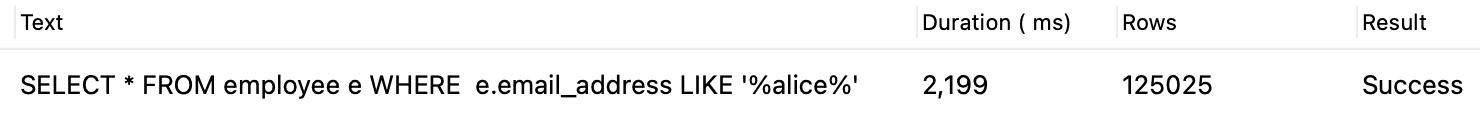
As you can see, the query takes longer time because it is not limited to 400.
Also from this case, there is something important that you need to know is "How the database execute the query?"
You can check it out by using this command EXPLAIN ANALYZE
-- First query
EXPLAIN ANALYZE SELECT * FROM employee e WHERE e.id = 102234;
-- Second query
EXPLAIN ANALYZE SELECT * FROM employee e WHERE e.email_address = 'bob.anderson567f0@example.com';
-- Third query
EXPLAIN ANALYZE SELECT * FROM employee e WHERE e.email_address LIKE '%alice%';
EXPLAIN ANALYZE Results
- First query and
EXPLAIN ANALYZEresult
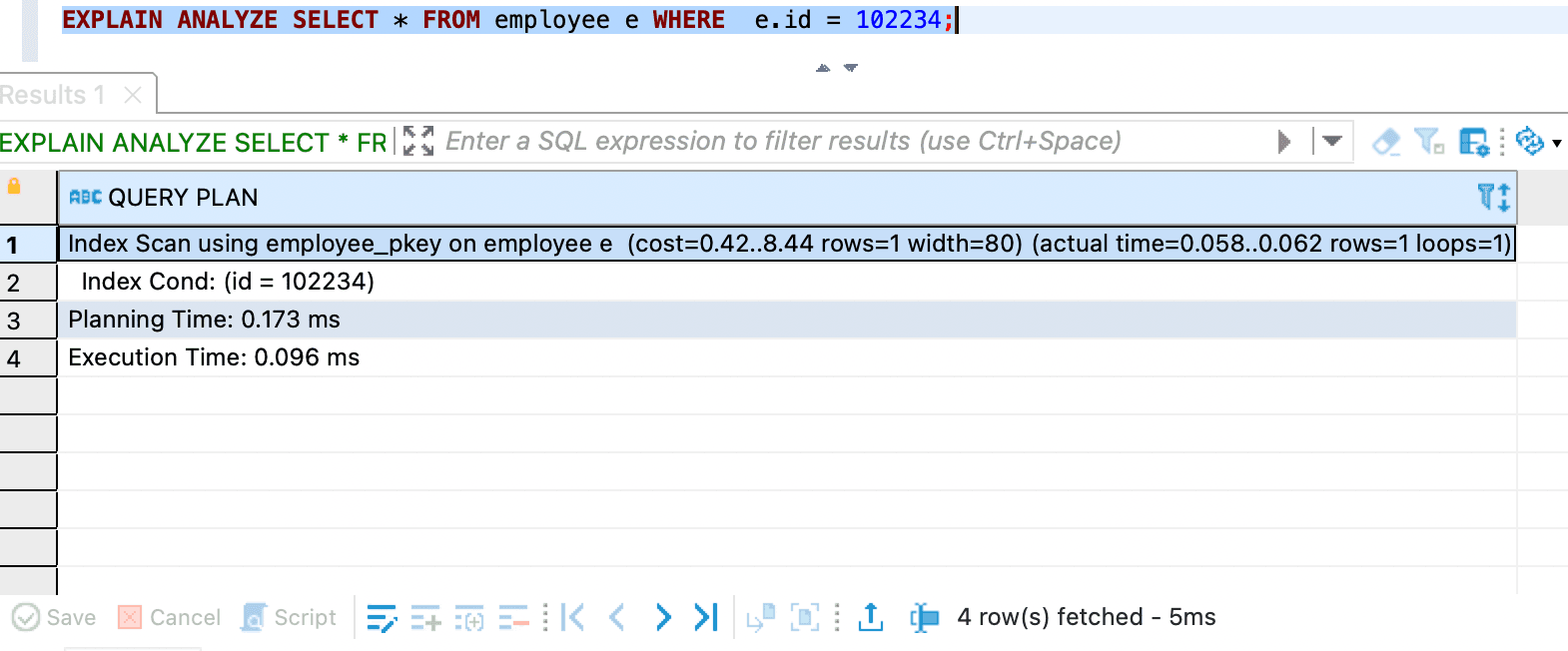
This query is using Index Scan.
- Second query and
EXPLAIN ANALYZEresult
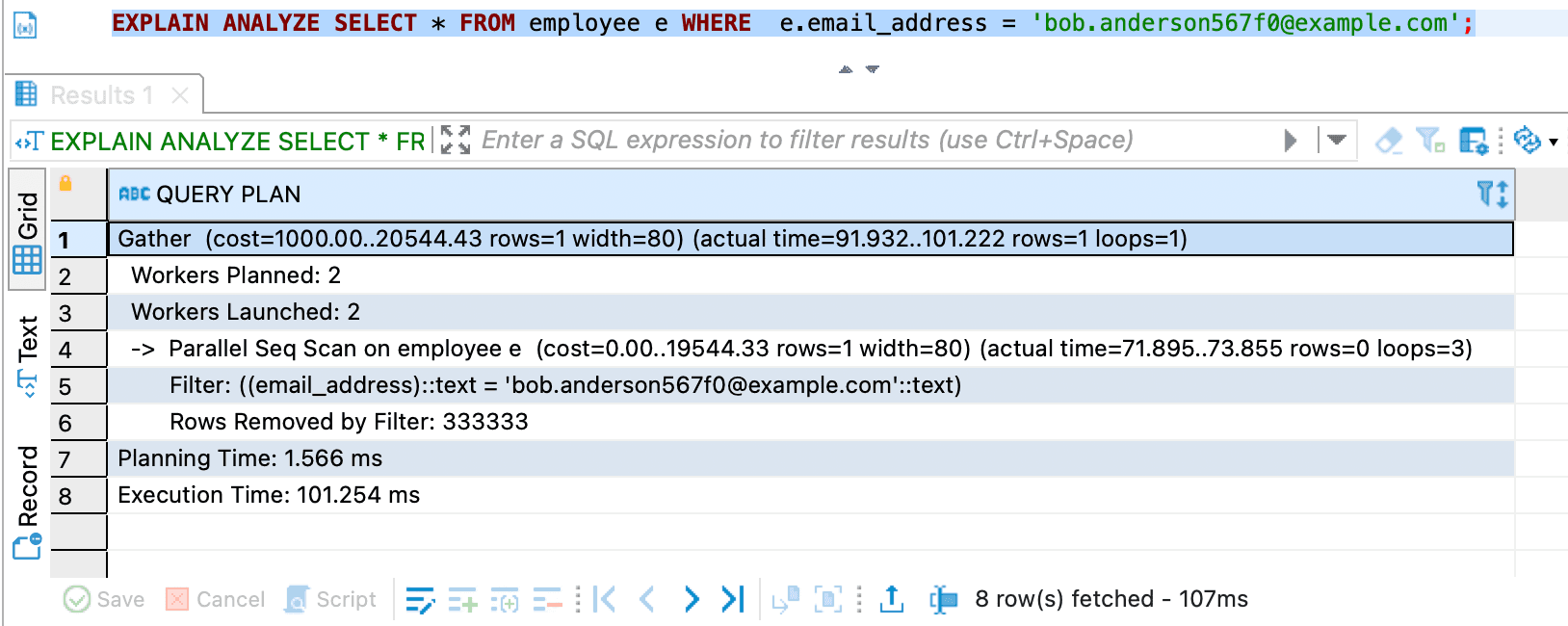
This query is using Seq Scan.
- Third query and
EXPLAIN ANALYZEresult
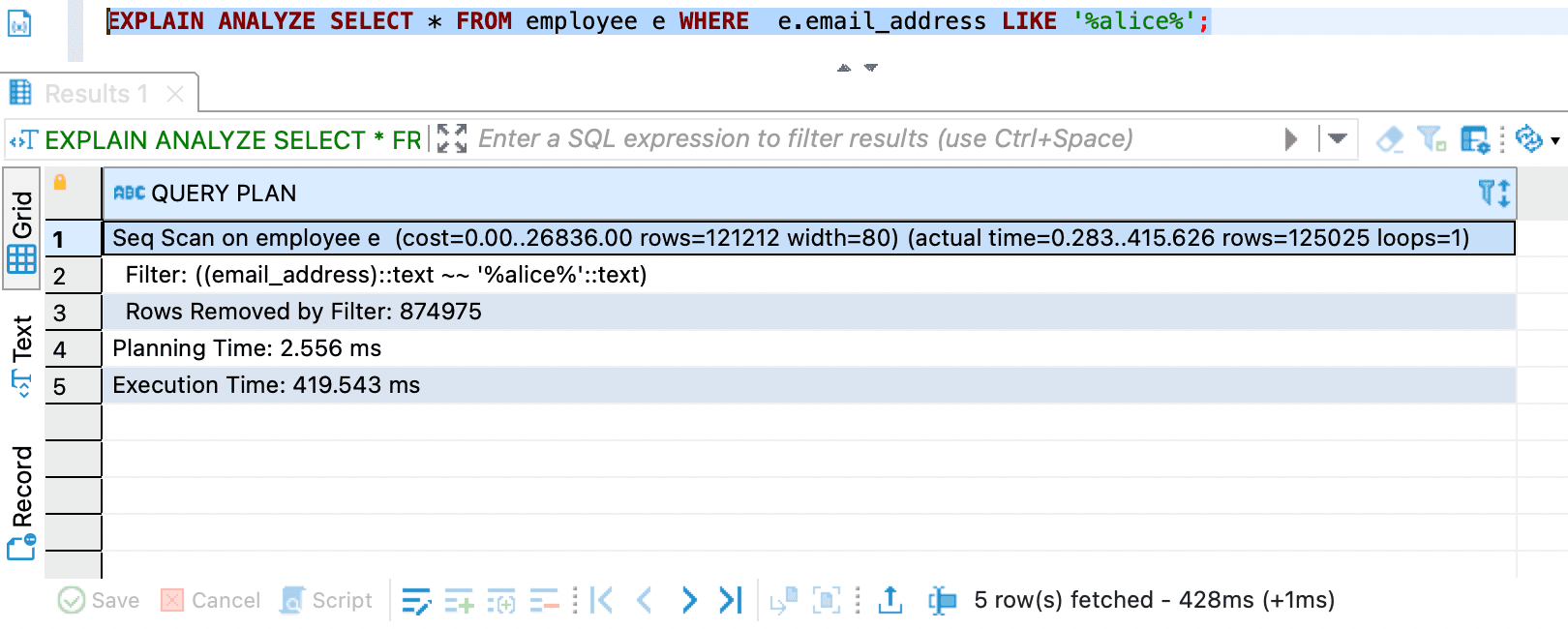
This query is using Seq Scan.
As you can see the second and third query performance are considered slow. Plus there are two interesting things e.g. Index Scan and Seq Scan.
What is Index Scan
An Index Scan in PostgreSQL refers to a query execution strategy where the database uses an index to locate rows in a table. Instead of scanning the entire table (a sequential scan), PostgreSQL leverages the index to retrieve only the relevant rows, making the query faster.
What is Seq Scan
A Seq Scan (Sequential Scan) in PostgreSQL is a query execution strategy where the database reads every row in a table to find the rows that match the query's conditions. It’s the simplest and most basic way PostgreSQL retrieves data from a table.
Parallel Seq Scan means PostgreSQL is scanning all rows in the employee table (in parallel with multiple workers) to find the matching row.
Create Database Index
Now you know that Sequential Scan can be very slow if the data size is very large or more than one million rows. Let's create database index in postgres for column email_address.
-- This is the command for creating index in postgresql
CREATE INDEX idx_name ON table_name (column_name);
-- This is the command for creating employee.email_address index
CREATE INDEX employee_email_address_idx ON employee (email_address);
If you are using DBeaver you can see the indexes should be like this.

Let's try again our second and third query
- Second query with
EXPLAIN ANALYZE
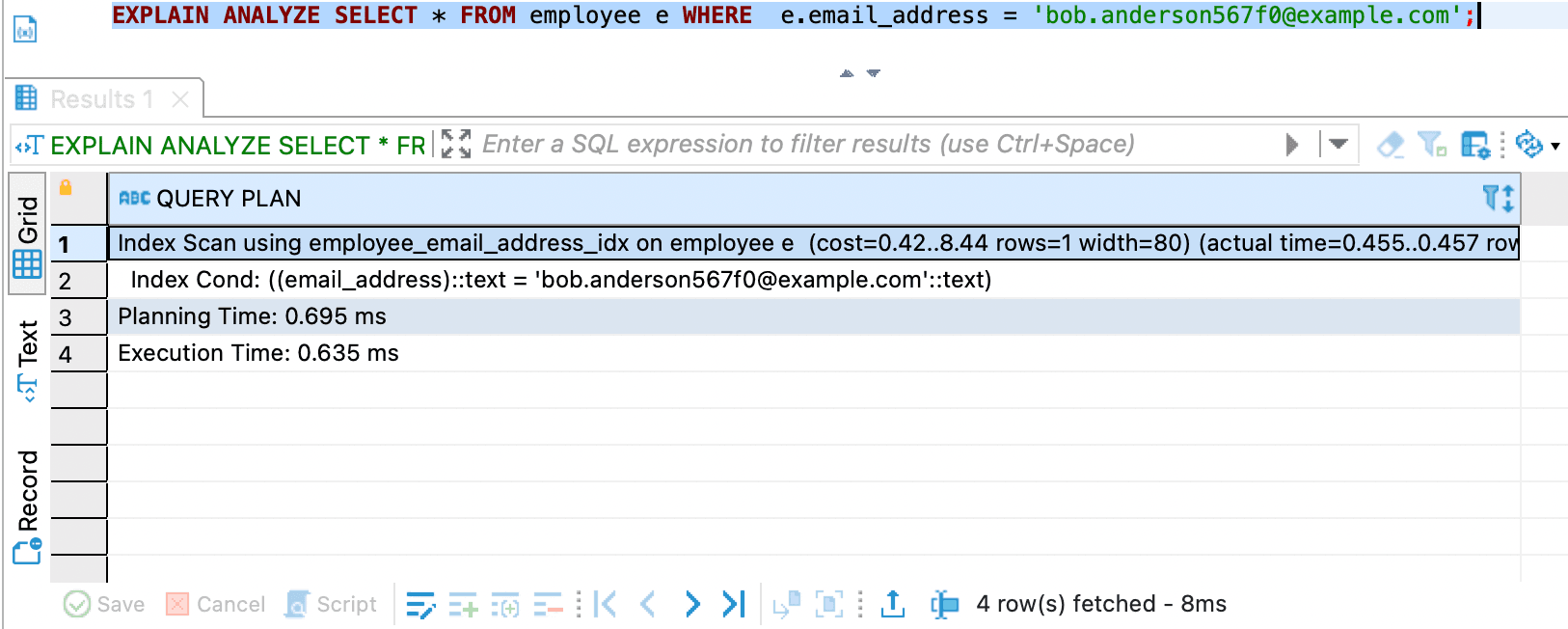
it is much faster than before using index execution time from 101.254 ms to 0.635 ms. The optimized execution is about 159 times faster than the original execution time.
- Third query with
EXPLAIN ANALYZE
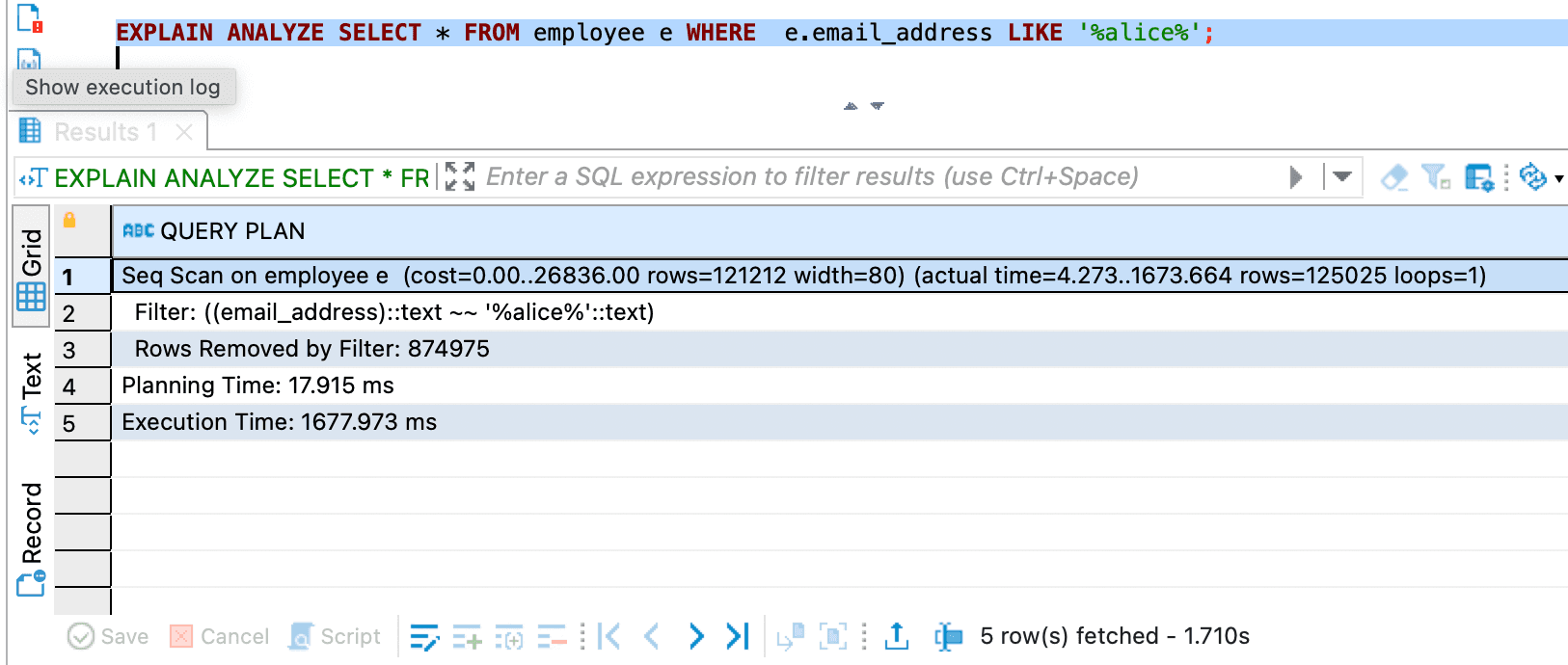
As you can see, the third query is not using index scan.
That is because the
employee_email_address_idx have not been optimized for pattern matching (using LIKE %some-string%)
How to solve the third query issue
We have two options:
- Redesign query to avoid leading
%and Recreate the index
-- you dont have to drop it, if you are using a new name index
DROP INDEX employee_email_address_idx;
CREATE INDEX employee_email_address_idx ON employee (email_address varchar_pattern_ops);
SELECT * FROM employee e WHERE e.email_address LIKE 'alice%';
this is the query result
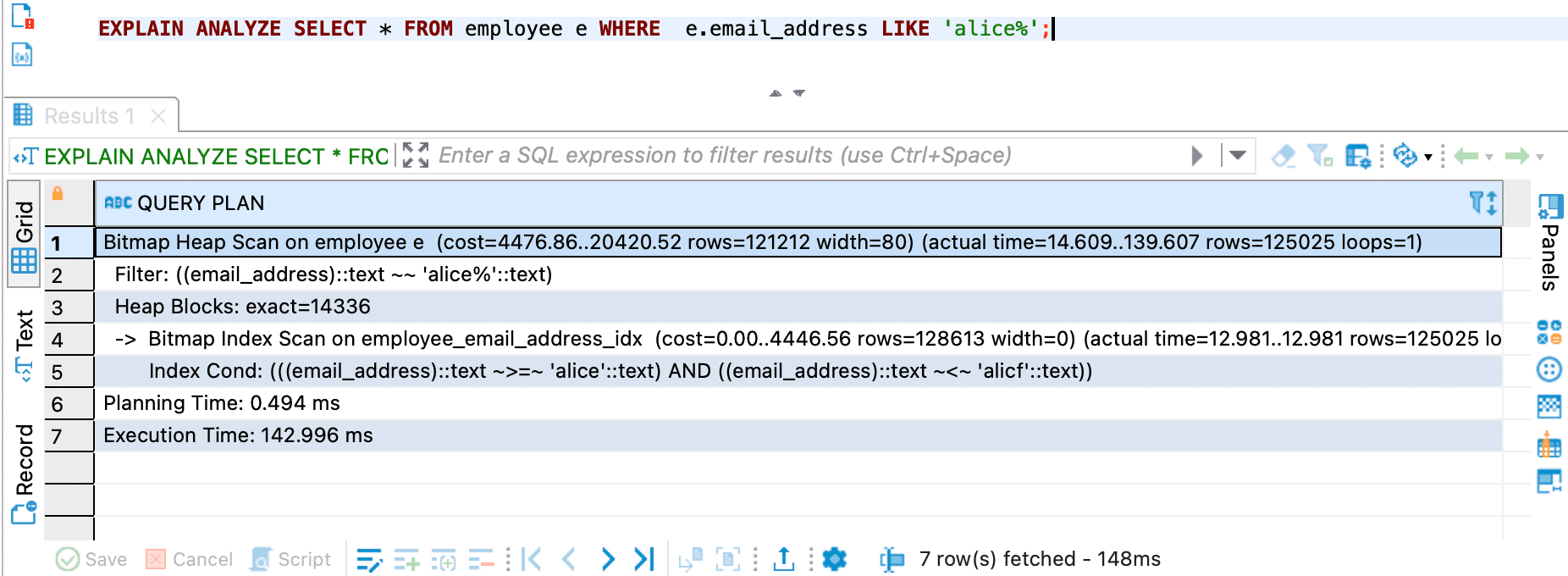
it is using Bitmap Heap Scan and Bitmap Index Scan and it is faster than using the previous query and previous database index. You can learn more about Bitmap Heap Scan and Bitmap Index Scan at the bottom of this blog post.
- Use PostgreSQL's full-text search with a
GINindex and use extensionpg_trgm.
I will write more about this in the next blog post.
Another query case
Let's try to select the data that is not exist in our database
-- there is no email in the table employee with prefix 'joyboy'
EXPLAIN ANALYZE SELECT * FROM employee e WHERE e.email_address LIKE 'joyboy%';
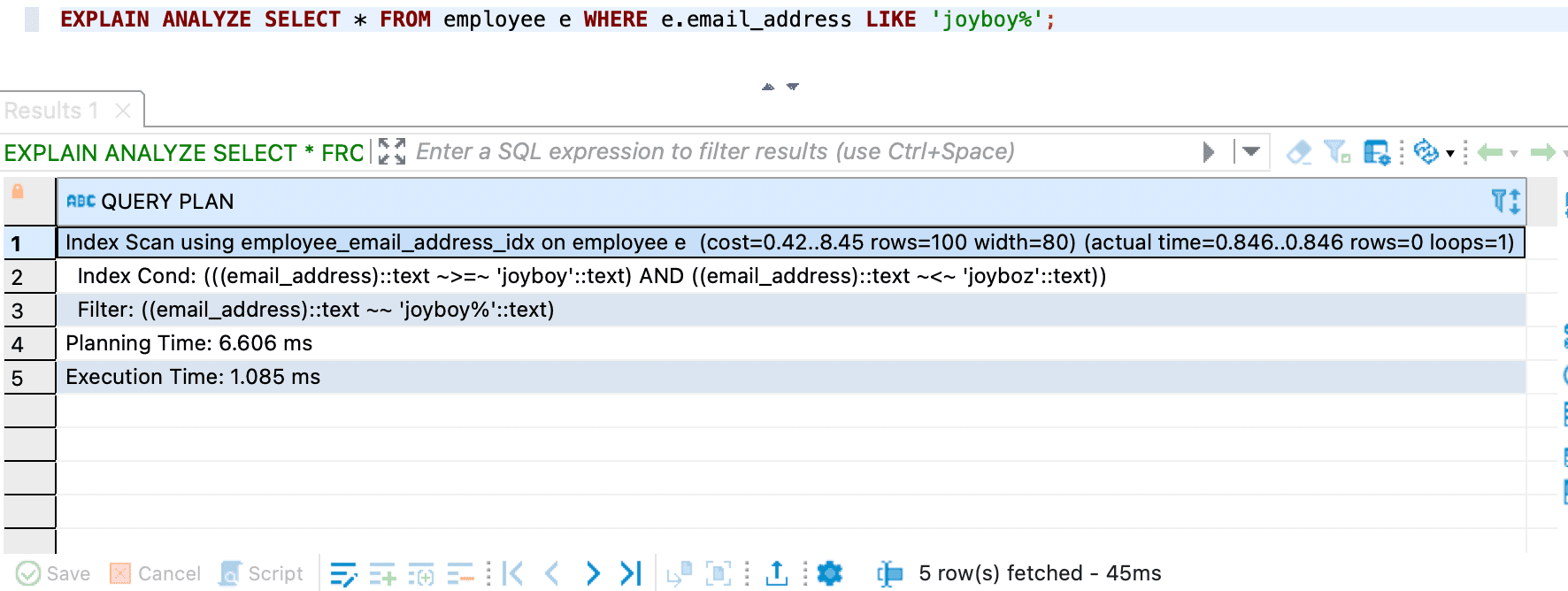
the query is using index scan, so it is very fast.
then if you drop the Index
DROP INDEX employee_email_address_idx;
-- then run this query
EXPLAIN ANALYZE SELECT * FROM employee e WHERE e.email_address LIKE 'joyboy%';
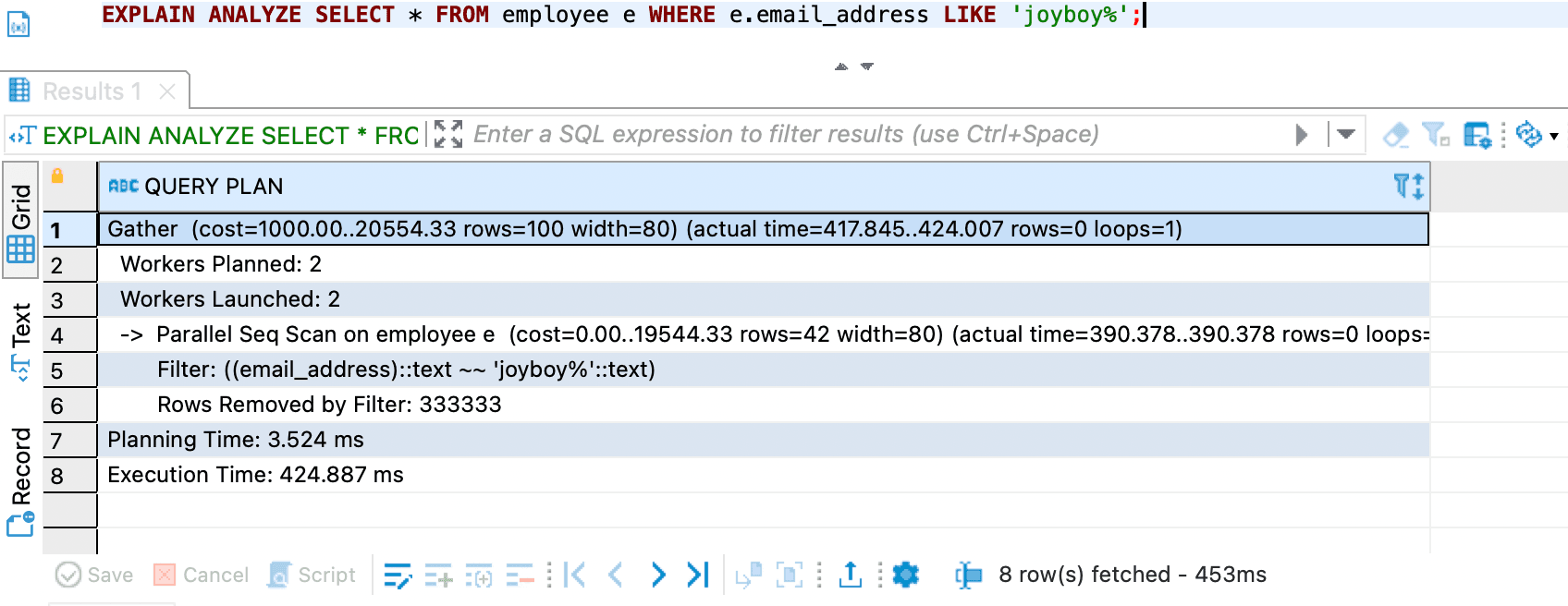
the query is very slow.
Types of Indexes in PostgreSQL
PostgreSQL provides several types of indexes, each optimized for different types of queries:
- B-Tree (default)
- Hash
- GiST
- SP-GiST
- GIN
- BRIN
- Unqiue Index
- Indexes on Expressions
- Partial Index
Bonus tips
B-tree index is allowing efficient lookups for
- Equality conditions (exact match):
WHERE column = value - Range conditions:
WHERE column > value or WHERE column < value - Prefix searches:
WHERE column LIKE 'prefix%'
You can use this command to force postgres to use Index Scan.
SET enable_seqscan = OFF;
When you are building a backend system,
it will be much better to create index when the data inside the table is relatively small
or during the development phase (not deployed in production).
When you run the CREATE INDEX on a database production environment
and the data is 1 million rows, it takes a few seconds to complete the indexing process
and will locking out writes.
Don't worry if you already have an existing database with very large size and does not have index. You can still implement it without locking out the writes. I will write more about it in the next blog post.
Closing
You can exploring more about Database Index in postgresql.
I hope this blog post is very useful for you and make you understand how to use Database Index.
See you soon in the next blog post. Thank you for reading and for your attention.
Learn more
find out more about